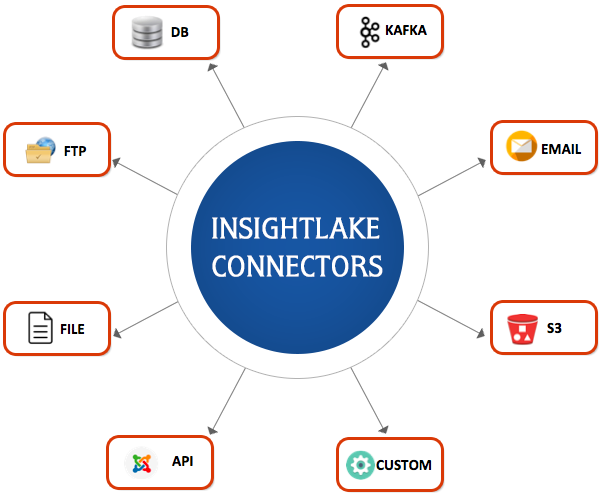
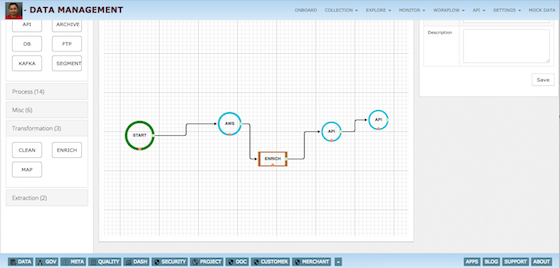
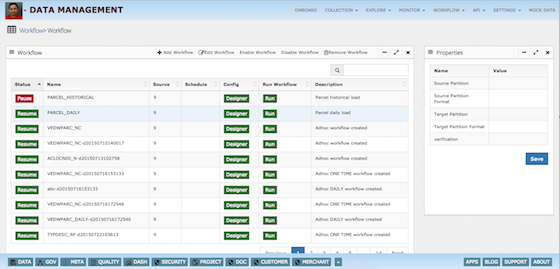
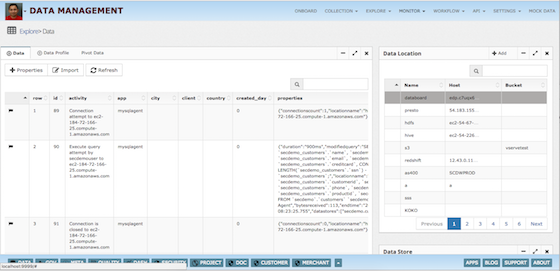
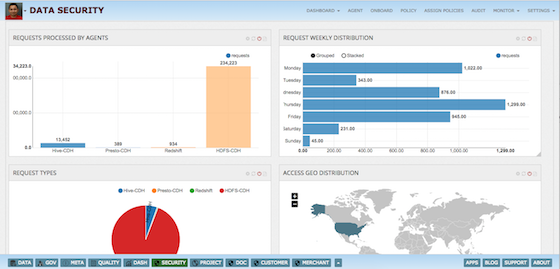
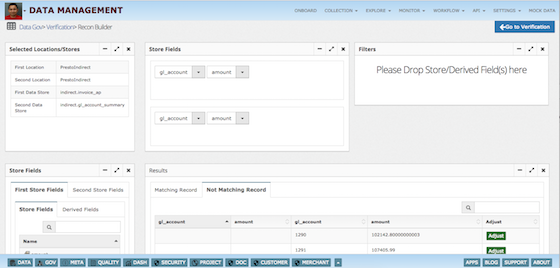
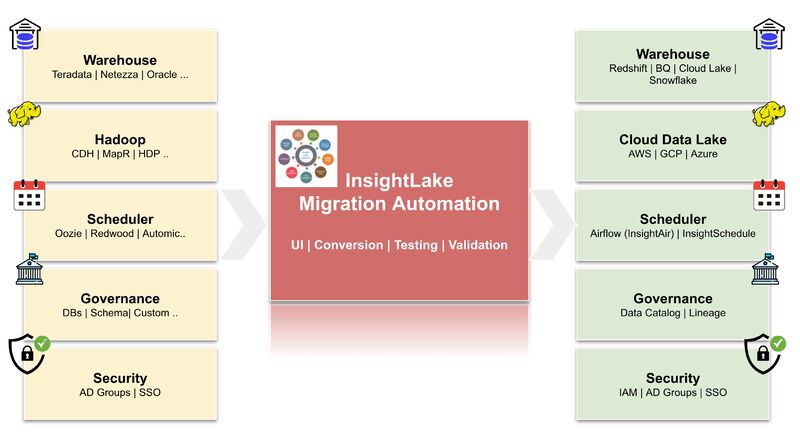
Data Management - Collect process & analyze data
- Many connectors to import and export data
- Drag and drop real time/batch pipeline designer
- Prepare, ingest and transform data quickly
- Explore, Reconcile and manage SLA
- Migrate, data pipelines using Automation