
If you need to shop something then you go to a store or website. You can easily search a product by its name, or features. You can also navigate through categories to reach to the right set of products. Businesses catalog their products to make discovery
easy. They also recommend similar or linked products to improve user experience.
Now if we take the same example for data lakes, where many structured, unstructured data sets are stored and are growing rapidly. Manually building a catalog for these big data sets is a very costly and time consuming process.
Many times its hard to find right people to know about the field level details. Without data catalog its very hard for business or data scientists to discover or understand data. They will have to rely on manual discovery. Companies
should setup an automated & curated governed process to build an approved business data catalog, which builds trust in the organization.
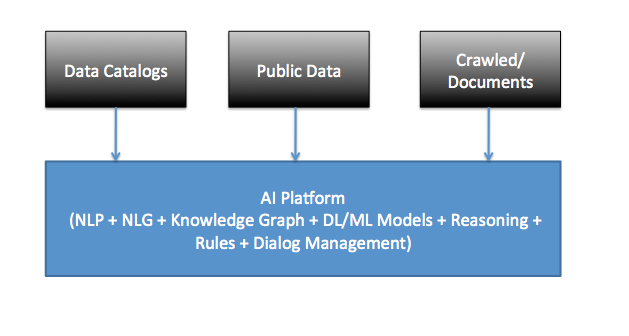
InsightLake Data Catalog solution unlocks the value of enterprise data lakes by building self service & governed centralized data catalog. It enables business users and data teams to find information easily. It allows companies to discover & enrich technical or business metadata, automatically annotate or tag data sets, curate and store metadata within data or externally. It also allows easy data exploration, collaboration and business information creation at various levels like domain, store, field or cell. InsightLake solution leverages machine learning & business curation to automatically catalog data assets in Big data environment with governed process.
Information catalog provides information about what data is available to business or data users, who owns the data, source of data, linked data sets, semantic meaning of data etc. Information catalog helps companies to share governed and curated data between various teams and make it more data driven.

Information catalog process starts with defining enterprise standards around tagging, data domains, business context, data owners and glossary.
Data catalog solution enables companies to build catalog from various data sources like Relational databases, Hadoop, File systems etc. It indexes data, extracts information and adds a metadata information layer to build a rich information catalog.

Data catalog solution allows easy discovery of data. Using intuitive UI an analyst can register data source and discover data sets.
InsightLake automatically profiles the data and links it with appropriate data domain hierarchies. It also classifies data using various tags. It uses machine learning and semantic topic models to do data classifications.
Data can come from various sources but some may be linked. InsightLake profiles the data sets and discovers the relationship between them. It shows linked data sets in the search results.
InsightLake stores data catalog in Lucene based search stores like Elastic Search or SOLR. Audit logs for the catalog changes are also stored for compliance.
InsightLake enables governance by allowing teams to follow approval process, by capturing data lineage and ensuring appropriate data usage for sensitive data. Solution integrates with Cloudera Navigator and Hortonworks Atlas for data lineage. Simple UI enables data stewards and business analysts to manage rules, roles and data access. Sensitive data is automatically tagged and access policies are defined.
InsightLake allows business and data stewards to validate, approve and curate information about data. Easy to use approval process establishes governed process to build trust and consistency about data.
Easy to use search UI allows exploration of data catalog using keywords and tags. It also allows filtering based on various facets or data hierarchies. It enables external applications to use REST APIs for catalog exploration. It allows teams to collaborate and enrich information about data.